Time Machine dans la course au FET Flagship européen

© 2018 EPFL DHLAB Venise Piazza San Marco
2018 est une année charnière pour le projet Venice Time Machine. Lancé en 2012, il arrive à mi-parcours, marqué par deux étapes majeures. D’une part, la volonté de donner une dimension européenne au concept de Time Machine. D’autre part, l’ouverture au public et aux historiens des plus de 2 millions de documents déjà numérisés.
«Tout ce qui est antérieur à l’an 2000 n’existe pas, car il n’y a pas de support pour y accéder». Le propos de Frédéric Kaplan est radical. Le directeur du Laboratoire d’humanités digitales s’inquiète d’un monde où seules les informations numérisées sont accessibles, jetant aux oubliettes toutes celles qui vieillissent sur d’autres supports. «Il y a urgence à faire un pont entre les deux. Il faut aussi vivre avec le passé.»
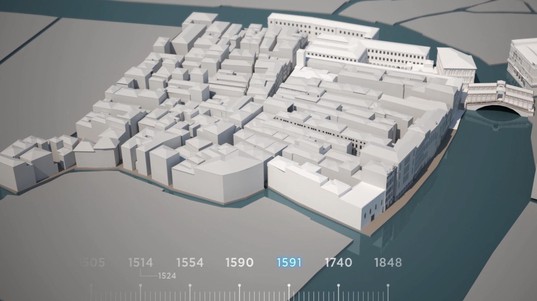
Le projet Venise Time Machine (VTM) n’est autre que l’établissement de ce pont entre passé et présent. Il vise à construire, à partir de millions de documents historiques aux formats hétéroclites, un modèle multidimensionnel de la ville de Venise, dans l’espace et le temps sur les 1000 dernières années. Lancé en 2012, VTM arrive aujourd’hui à mi-parcours. Une échéance marquée par deux étapes cruciales.
Cartographier 5000 ans d’histoire européenne
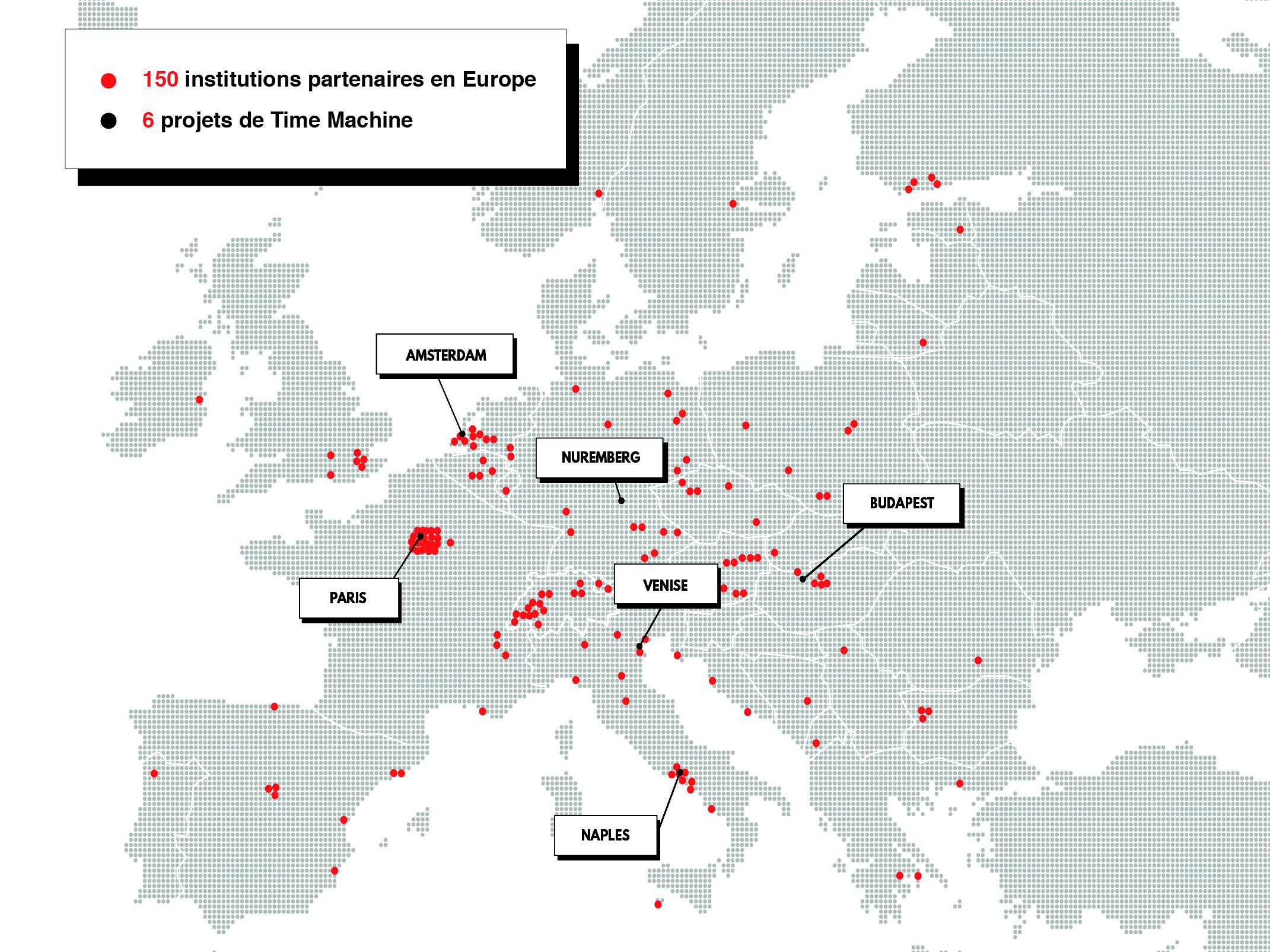
La première est l’extension du projet de Time Machine à l’échelle européenne. Dans un manifeste rédigé en 2016, Frédéric Kaplan imaginait que toutes les universités se réuniraient et travailleraient ensemble pour partager le patrimoine culturel européen. Le document a reçu un écho inattendu, plusieurs délégués des pays représentés à la Commission européenne ont été séduits et l’ont défendu. C’est ainsi que le manifeste est devenu le premier document concret d’une proposition de FET Flagship au Conseil européen. Un programme qui permet d’assurer le financement d’une recherche pendant 10 ans à hauteur d’un milliard d’euros.
Le but aujourd’hui est de construire un simulateur à grande échelle pour cartographier 5000 ans d’histoire. A ce jour, 165 institutions partenaires issues de 32 pays ont constitué un consortium dans le but de développer de nouvelles technologies de numérisation, d'analyse, d'accès, de préservation et de communication du patrimoine culturel à grande échelle. Le dossier a été soumis ce mois. La course au FET Flagship comprend plusieurs étapes et le verdict sera rendu l’an prochain.
Plusieurs Time Machine déjà en marche
Certaines villes n’ont toutefois pas attendu l’échéance européenne pour lancer leur Time Machine. Amsterdam (photo ci-dessus), Nuremberg, Paris, Jérusalem, Budapest et Naples ont décidé de plonger dans leurs archives afin de créer une immense banque de données du passé reliée à l’échelle nationale et européenne. Pourquoi? Julia Noordegraaf, professeure du patrimoine numérique à l'Université d'Amsterdam, et Sander Münster, qui dirige le Département de la conception et de la production des médias à l'Université technique de Dresde (photo ci-contre), nous ont répondu. Interview: cliquez ici (pdf)
La seconde étape est celle de la mise en ligne d’interfaces de recherche permettant d’explorer les plus de 2 millions de documents déjà scannés. Le chemin parcouru en cinq ans – deux seulement depuis que la numérisation a commencé – se mesure d’abord en chiffres: 190 000 documents d’archives d’Etat, 720 000 documents photographiques provenant de la Fondation Cini, 3000 volumes sur l’histoire de la ville issus des grandes bibliothèques de la cité ont été scannés. «C’est moins de 1% de ce qui existe, c’est infini!», lâche Frédéric Kaplan, avec encore davantage d’enthousiasme. Mais c’est ainsi qu’a pu être révélé un trafic d’œuvres d’art entre les Pays-Bas et l’Italie!
Des dizaines de milliers d’annotations
Pour parvenir à ce résultat, il a fallu commencer par construire les technologies nécessaires pour scanner et numériser rapidement des kilomètres de documents, parfois vieux d’un demi-millénaire. Un premier scanner semi-automatique est utilisé pour les manuscrits et documents fragiles de grand format a été construit. Un autre, à balayage robotique, tourne les pages automatiquement des journaux et des livres. Un troisième, développé avec Adam Lowe de Factum Arte, est capable de numériser un document photographique recto verso toutes les 4 secondes.
Au-delà de la numérisation proprement dite, plus de 160 000 transcriptions manuelles de noms , lieux, mots-clés ont été produites par les historiens, paléographes et archivistes sur les sources documentaires. Grâce à ces annotations sur les documents d’archives, un système de reconnaissance automatique des écritures a permis d’extraire les informations des documents. «Il faut par exemple gérer la diversité des écritures et les multiples abréviations qui n’étaient pas standardisées, explique Sofia Ares Oliveira, chercheuse au Laboratoire d’humanités digitales. Nous avons montré à l’ordinateur des exemples afin qu’il apprenne à apprendre.» Le système est ainsi capable de transcrire des mots non annotés avec un taux d’erreur sur les caractères de 4% sur chaque caractère. «C’est un peu comme lorsqu’on fait une faute de frappe dans un moteur de recherche: c’est suffisant pour que le système de recherche propose des résultats pertinents et on comprend de quoi il s’agit», précise la chercheuse.
, lieux, mots-clés ont été produites par les historiens, paléographes et archivistes sur les sources documentaires. Grâce à ces annotations sur les documents d’archives, un système de reconnaissance automatique des écritures a permis d’extraire les informations des documents. «Il faut par exemple gérer la diversité des écritures et les multiples abréviations qui n’étaient pas standardisées, explique Sofia Ares Oliveira, chercheuse au Laboratoire d’humanités digitales. Nous avons montré à l’ordinateur des exemples afin qu’il apprenne à apprendre.» Le système est ainsi capable de transcrire des mots non annotés avec un taux d’erreur sur les caractères de 4% sur chaque caractère. «C’est un peu comme lorsqu’on fait une faute de frappe dans un moteur de recherche: c’est suffisant pour que le système de recherche propose des résultats pertinents et on comprend de quoi il s’agit», précise la chercheuse.
Trois outils pour plonger dans les données
Grâce à ce travail, les scientifiques mettront en ligne d’ici à l’été un premier moteur de recherche, baptisé Canvas. Il permet d’accéder aux documents d’archives d’Etat numérisés dans leur version originale, mais surtout d’effectuer des recherches par mot-clé (une personne, un lieu, une date…) dans les contenus. L’outil fonctionne comme un wiki, ce qui permet aux utilisateurs autorisés de corriger les erreurs de lecture du système qu’ils rencontrent et d’améliorer ainsi en continu sa performance.
Le second travail de numérisation a été effectué sur la collection iconographique de la Fondation Cini. Sur le million de photos d’art que possède la Fondation, un premier fonds de 370 000 images a été numérisé. A nouveau, des milliers d’annotations manuelles ont été nécessaires pour entrainer l’ordinateur. Résultat, l’interface Replica proposera une recherche non seulement textuelle, mais surtout visuelle des documents, établissant des connexions entre les images. «La machine a appris à faire des liens entre la composition, la position des personnages, les différents éléments ou motifs afin d’établir des similitudes entre images. Aux historiens de l’art ensuite d’écrire leur histoire», explique Benoît Seguin qui a conçu ce moteur de recherche dans le cadre de sa thèse qu’il défendra durant l’été.
Enfin, la troisième concrétisation de cette numérisation met les ouvrages et les journaux scientifiques des grandes bibliothèques de la Sérénissime à portée de clics. Près de 3000 ouvrages sur Venise, du 19e au 21e siècle, et plus de 100 ans de publications scientifiques sur la ville ont été numérisés dans le cadre de Linked Books, un projet soutenu par le FNS, idée et développé par les chercheurs Giovanni Colavizza et Matteo Romanello avec Frederic Kaplan. Un système ad hoc a été développé pour en extraire automatiquement et après chercher les citations. Baptisé Venice Scholar, l’interface permet d'étudier l'historiographie vénitienne à travers ces citations. Comme les deux autres, le système est ouvert et la base de données peut accueillir de nouvelles intégrations. Ces sources secondaires sont également reliées aux sources primaires de Canvas.
Dossier de presse:
https://go.epfl.ch/VTMFetFlagship
Contacts :
Anne-Muriel Brouet Service de presse EPFL
+41 21 69 32442
[email protected]
Sandy Evangelista Service de presse EPFL
+41 21 69 32185
+41 79 502 81 06
[email protected]
Frederic Kaplan Laboratoire d'humanités digitales EPFL
+41 21 69 30253
+41 21 69 31901
[email protected]


Images à télécharger