NTK: percer les mystères du deep learning

Ce n'est pas un RN. https://stocksnap.io/
Des chercheurs de la chaire de théorie statistique des champs (CSFT) ont trouvé une nouvelle façon de comprendre les réseaux neuronaux artificiels. Leur article de 2018 a suscité beaucoup d'attention de la part de la communauté scientifique et est maintenant fréquemment utilisé par les chercheurs lorsqu'ils veulent comprendre la formation des grands réseaux de neurones.
Les réseaux neuronaux artificiels (RN) sont au cœur de la révolution du Deep Learning en intelligence artificielle, qui a connu des progrès spectaculaires au cours de la dernière décennie : Les RN ont permis des percées dans de nombreuses applications, de la vision par ordinateur au traitement du son, en passant par les jeux de société et les jeux vidéo, la conduite de véhicules, la traduction et la génération de textes ou encore la résolution de problèmes issus de la biologie et de la chimie.
Si les RN ont fondamentalement transformé la façon dont nous traitons les données du monde qui nous entoure, elles semblent théoriquement complexes et leur fonctionnement reste en quelque sorte mystérieux : l'élaboration d'un cadre mathématique pour comprendre les RN est largement considérée comme un problème central dans ce domaine.
Inspiré des réseaux de neurones biologiques, un RN traite les signaux d'entrée en appliquant une séquence de transformations à travers plusieurs couches de neurones : c'est très similaire à la façon dont le cortex visuel traite les informations provenant des nerfs optiques. Chaque connexion entre les neurones a un paramètre d'intensité: les RN modernes peuvent avoir des milliards de ces paramètres, qui sont délicatement ajustés pour leur permettre d'effectuer diverses tâches.
Contrairement aux programmes informatiques classiques qui sont explicitement conçus pour résoudre une tâche donnée, les RN sont formés pour l'accomplir : par exemple, pour former un réseau à identifier correctement un chat dans une image, on lui donne un ensemble de données d'images avec des étiquettes indiquant où les chats apparaissent. La formation est effectuée par optimisation : une fonction de score mesure la qualité du RN dans sa tâche, et les paramètres du RN sont progressivement ajustés pour l'améliorer. Si cette procédure d'optimisation donne des résultats impressionnants en pratique, la compréhension d'une telle procédure sur des milliards de paramètres semble être une tâche ardue (comme le savent les étudiants en Analyse I & II, il peut être très difficile d'optimiser une fonction ne serait-ce que d'un ou deux paramètres).
En 2018, Arthur Jacot, Franck Gabriel et le professeur Clément Hongler de la chaire de théorie des champs statistiques (CSFT) ont trouvé un nouveau lien entre les réseaux de neurones et un autre domaine du Machine Learning, appelé Kernel Methods (méthode de noyaux). Plus précisément, ils ont découvert qu'un RN peut être décrit à l'aide de son NTK (Neural Tangent Kernel , ou Noyau Neural Tangent). Cela donne une nouvelle compréhension mathématique de l'optimisation des RN avec de nombreux paramètres. Cette découverte apporte en particulier un éclairage sur deux questions fondamentales : la convergence et la généralisation des RN.
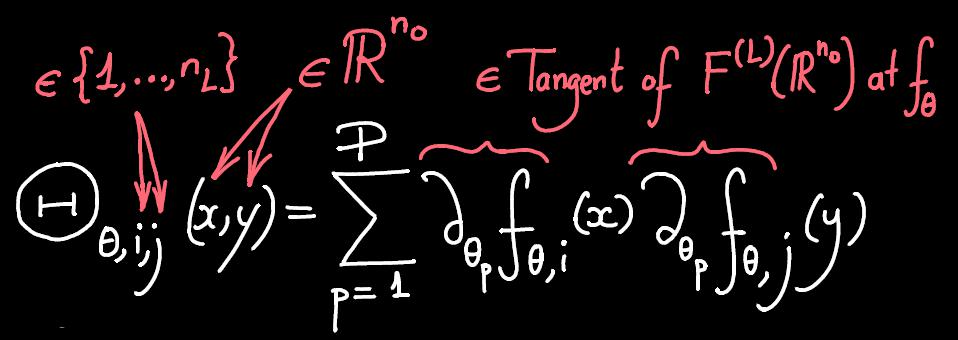
Le problème de la convergence est la question de savoir si la formation des RN atteindra l'optimum pour leur score ou s'ils seront bloqués quelque part avant. Cette question était restée sans réponse et très débattue jusqu'alors : certains ont suggéré que cela revenait à se déplacer dans un paysage montagneux avec beaucoup de vallées et de cols, tandis que d'autres ont suggéré que le paysage était beaucoup plus lisse. En utilisant le NTK, Jacot, Gabriel et Hongler ont pu montrer que pour les très grandes RN, la question devient étonnamment plus facile et qu'ils atteignent généralement leur optimum global : le modèle du paysage lisse s'applique ici. En outre, la vitesse de convergence et la nature de l'optimum atteint par le RN peuvent être comprises en termes de son NTK.
La question de la généralisation est de savoir comment un RN traitera les données avec lesquelles il n'a pas été formé. Se contente-t-il d'apprendre par cœur les exemples qui lui ont été donnés ou est-il capable de généraliser et de donner des prévisions correctes au-delà de ces exemples ? En utilisant le NTK, Jacot, Gabriel et Hongler ont donné une nouvelle formule expliquant comment un RN effectue des prédictions et des extrapolations à partir des données avec lesquelles il a été formé. Grâce à cette formule, la généralisation des RN peut être mise en relation avec celle des Kernel Methods, pour lesquelles des outils théoriques sont plus facilement disponibles.
Depuis 2018, le NTK a suscité beaucoup d'attention de la part de la communauté scientifique. L'article original a déjà récolté plus de 600 citations sur Google Scholar. Il est désormais fréquent que les chercheurs utilisent le NTK pour comprendre la formation des grands réseaux de neurones. Une nouvelle bibliothèque de logiciels, appelée Neural Tangents, a été créée par Google pour calculer le NTK (vous pouvez taper pip install neural-tangents dans votre terminal pour l'installer). Le NTK a trouvé sa voie dans de nombreux contextes, allant des réseaux adversatifs générateurs (la manière dont les ordinateurs apprennent à faire des images réalistes par exemple) à l'apprentissage par renforcement (comment les ordinateurs jouent les uns contre les autres pour s'améliorer), en passant par les transformateurs (qui traitent de longues séquences, comme des textes).
Actuellement, une question centrale pour comprendre le fonctionnement du Deep Learning est de comprendre la nature précise et l'évolution des NTK pendant leurs formations : en particulier, la compréhension des réseaux de taille moyenne semble étonnamment plus difficile. Peut-être que pour comprendre les NTK, il faudra introduire un nouvel objet ?
Pour conclure, nous avons décidé de demander à un RN son avis sur la question. Voici ce qu'il nous a apporté.
>What do you think of the Neural Tangent Kernel ?
>You may be interested in the transcript of our talk at Deep Learning Summit. We’re very pleased to show you our demo on how we’re integrating Bluetooth technology into the Neural Tangent Kernel: Google researchers creating a neural network with auto-encoder and decoder layers, by teaching it to detect objects and specify their size. The neural network itself is trained using the good old tuning parameters (in this case three parameters).
Nous n'en sommes pas encore là, mais peut-être qu'un jour, les réseaux neuronaux pourront nous dire eux-mêmes comment ils fonctionnent !
Pour plus d'informations : https://en.wikipedia.org/wiki/Neural_tangent_kernel