EPFL Doctorate Award - 2022 - Lana Josipović

© 2022 EPFL
High-Level Synthesis of Dynamically Scheduled Circuits
EPFL thesis n°7211
Thesis director: Prof. P. Ienne
For the development of a radically new approach to the generation of efficient digital circuits from software programs.
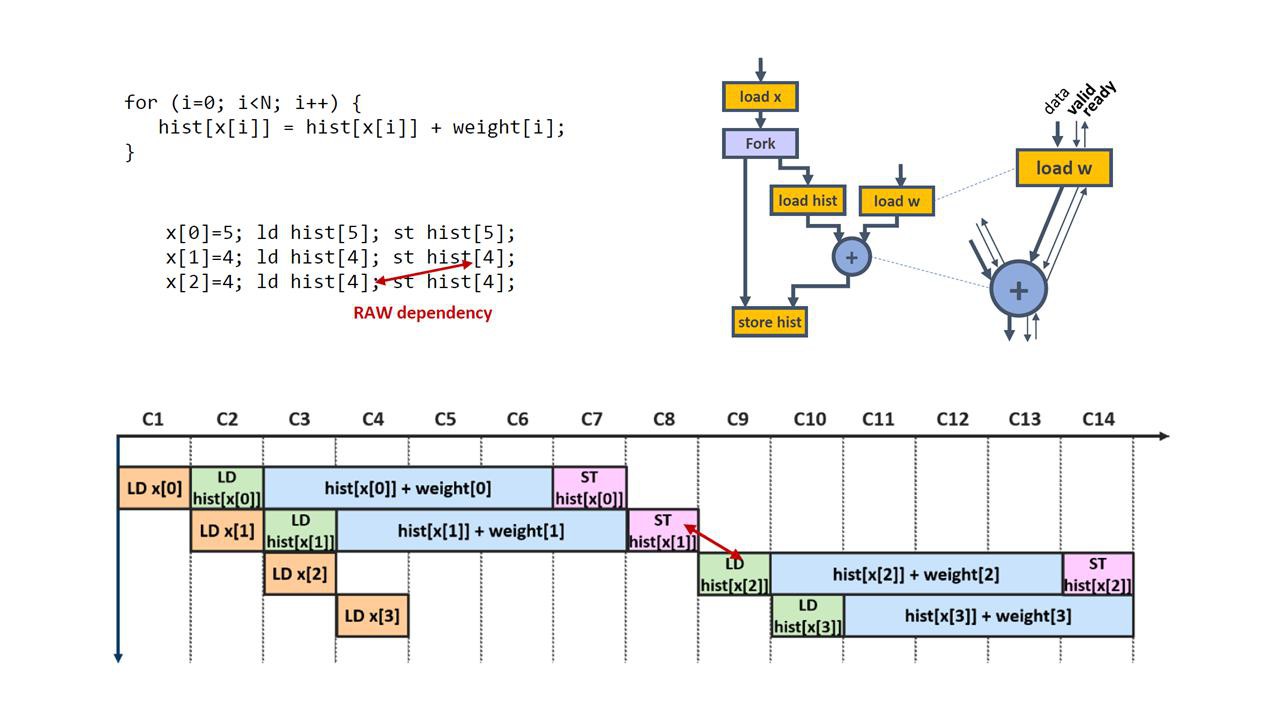
-Level Synthesis (HLS) tools generate hardware designs from high-level programming languages. These tools almost universally build datapaths that are controlled using a centralized controller which relies on a static, compile-time schedule to determine the cycle when each operation executes. Such an approach results in high-throughput pipelines in cases where memory accesses are provably independent and critical control decisions are determinable during code compilation. Unfortunately, when this is not the case, the tools must make pessimistic assumptions, yielding inferior schedules and lower performance. An alternative HLS approach is to create dataflow circuits out of high-level code. Dataflow circuits are built out of units which communicate using point-to-point pairs of handshake control signals; data is propagated from unit to unit as soon as memory and control dependences allow it and stalled by the handshaking mechanism otherwise. This distributed control mechanism effectively implements a dynamic schedule, where scheduling decisions are made locally in the circuit as it runs, hence achieving behaviors which are beyond the capabilities of statically scheduled circuits.
Although translating high-level code into dataflow circuits seems relatively straightforward, a naive translation is not sufficient to achieve functional correctness, high performance, and area efficiency. Firstly, without appropriate buffer placement and sizing, dataflow circuits exhibit only limited pipelining capabilities. Secondly, in the absence of a static schedule, resource sharing opportunities are difficult to identify; in addition, sharing may cause deadlock and compromise the functionality of the circuit. Thirdly, memory accesses in a dataflow circuit may execute in an order different than the one specified in the original program---a naive memory interface is not always sufficient to guarantee that all memory dependences are honored. Finally, standard dataflow circuits do not support speculation, i.e., the ability to execute some operations before it is certain whether they are correct or required, which prevents pipelining when a memory or a control dependence takes a long time to resolve.
The contribution of this thesis is to develop techniques that make dataflow circuits truly competitive in the HLS context. We first present a complete set of rules and transformations to create dataflow circuits out of high-level specifications (i.e., C/C++ programs). We detail a methodology to systematically place and size buffers in dataflow circuits to achieve high-throughput pipelines. We show how to automatically identify performance-acceptable resource sharing opportunities and describe a sharing mechanism which achieves functionally correct and deadlock-free dataflow designs. We detail the construction of a memory interface (i.e., a load-store queue) for dataflow circuits that can correctly handle memory accesses arriving out of order and show how to automatically customize this interface to a particular application. Further, we present a generic framework for handling speculation in dataflow circuits. Finally, we show that these techniques can reap significant area/performance benefits in appropriate situations.
All these features enable dataflow circuits to achieve dynamic behaviors similar to those of modern superscalar processors; we believe that these behaviors are key for HLS to be successful in new contexts and broader application domains.