Un programme capable de décrire vos photos

© Thinkstockphotos
Des chercheurs ont mis au point un algorithme capable de légender automatiquement vos photos, et même d’utiliser des phrases qui ne lui ont pas été apprises. Un système qui intéresse beaucoup Facebook.
Contrairement aux systèmes récemment présentés par Google ou Microsoft, l’algorithme développé par deux chercheurs de l’Idiap à Martigny, un institut de recherche affilié à l’EPFL, peut décrire une image sans réutiliser des légendes déjà apprises. Pour arriver à ce résultat, les chercheurs ont travaillé sur un programme capable de représenter dans des espaces vectoriels les images et leurs légendes, grâce à un analyse de la syntaxe des phrases.
«Quand on lui soumet une photo, le programme rapproche le vecteur de l’image avec celui des mots possibles, et choisit quels sont les groupes nominaux, verbaux et prépositions les plus probables», explique Rémi Lebret, doctorant spécialisé dans le Deep Learning à l’Idiap. Ce système peut ainsi trouver la description la plus probable pour une photo d'un homme qui fait du skateboard», même s’il n’en a jamais analysée auparavant: l'ordinateur découpe la photo en termes qu'il perçoit, comme «un homme, un skateboard, une rampe, et en verbes d'actions possibles, avant de proposer une phrase pour décrire l'image.
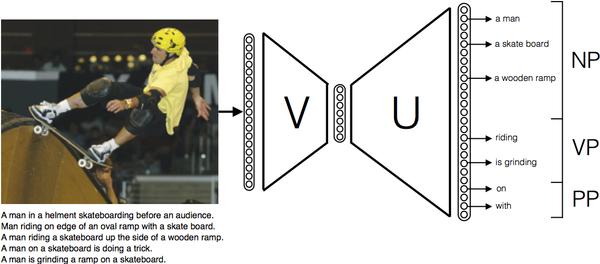
La bonne prédiction
Une approche différente des systèmes couramment utilisés, qui utilisent une description séquentielle en se basant sur des réseaux de neurones récurrents. «Ces derniers proposent un premier mot suivant l’image, puis ils l’utilisent pour prédire les suivants», explique le chercheur de l’Idiap Pedro Oliveira Pinheiro. Une manière de faire qui peut poser problème si le début de la phrase est mal prédit, car la légende sera forcément incorrecte. De plus, ces systèmes requièrent une phase d’entraînement plus longue, et ont tendance à recycler des légendes déjà utilisées.
Plus simple et efficace, la technologie développée par Pedro Oliveira Pinheiro et Rémi Lebret intéresse beaucoup les réseaux sociaux. Les deux chercheurs ont passé six mois en stage à Facebook, qui s’inspire de leur travail pour développer son modèle de légendes automatique destiné notamment aux personnes malvoyantes. Dans le futur, les deux chercheurs estiment que leur algorithme pourrait être amélioré grâce à des modèles de langage plus complexes et incorporant des bases de données plus larges.
Cette recherche a été soutenue par la Fondation Hasler et par Facebook.
Référence :
Remi Lebret, Pedro O. Pinheiro, Ronan Collobert, Phrase-Based Image Captioning. (ICML 2015)